Nå har du rotet deg bort i ting som virker veldig enkelt, men som er veldig komplisert, i det minste kan det være det.
Det mest vanlige er som Dostojevskij skriver ovenfor, å beregne en avstand, altså hvor mange tegn som må endres.
I sin enkleste form er dette en
Hamming avstand, men i praksis så brukes som oftest litt mer avanserte algoritmer som tar hensyn til hvor mange tegn som settes inn, slettes eller byttes ut, for å få riktig resultat.
Dette kalles
Levenshtein algoritmen, og den er egentlig ganske enkel, men ikke alltid veldig nøyaktig, den er likevel veldig mye brukt innen programmering.
En liten forbedring ville være en
Damerau–Levenshtein avstand i stedet, den tar også høyde for bytting av to tegn, altså at "japna" egentlig er "japan" osv. I javascript vil det se noe slikt ut
PHP:
function levenshtein(s, t) {
var d = [];
var n = s.length;
var m = t.length;
if (n == 0) return m;
if (m == 0) return n;
for (var i = n; i >= 0; i--) d[i] = [];
for (var i = n; i >= 0; i--) d[i][0] = i;
for (var j = m; j >= 0; j--) d[0][j] = j;
for (var i = 1; i <= n; i++) {
var s_i = s.charAt(i - 1);
for (var j = 1; j <= m; j++) {
if (i == j && d[i][j] > 4) return n;
var t_j = t.charAt(j - 1);
var cost = (s_i == t_j) ? 0 : 1;
var mi = d[i - 1][j] + 1;
var b = d[i][j - 1] + 1;
var c = d[i - 1][j - 1] + cost;
if (b < mi) mi = b;
if (c < mi) mi = c;
d[i][j] = mi;
//Damerau transposition
if (i > 1 && j > 1 && s_i == t.charAt(j - 2) && s.charAt(i - 2) == t_j) {
d[i][j] = Math.min(d[i][j], d[i - 2][j - 2] + cost);
}
}
}
return d[n][m];
}
Merk at PHP har denne innebygget ->
http://php.net/manual/en/function.levenshtein.php
Så finnes det hundrevis, sikkert tusenvis av alternativer og muligheter.
For eksempel
Soundex algoritmen som ble patentert allerede i 1918, som gjør noe av det samme, men i stedet for å se på kun bokstavene, så sammenlignes det fonetisk, altså hvordan bokstavene virkelig høres ut, og det er jo slik at mange skrivefeil er nettopp fordi brukere skriver ting slik de høres ut, uten at det nødvendigvis er grammatisk riktig. Denne algoritmen benyttes i mange store databaser, og finnes i MySQL, Postgre osv.
Det er selvfølgelig mange nyere og bedre algoritmer som er bygget på toppen av Soundex igjen.
Et annet alternativ er algoritmer som tar hensyn til keyboard layout, ettersom det er vanlig å trykke på bokstaven ved siden av på tastaturet, altså at man bommer på en tast, og her brukes ofte variasjoner av
n-gram, som regel trigram, og en litt mer avansert versjon av n-gram som kalles q-gram, som regner ut summen av den absolutte forskjellen mellom vektorene i n-gram resultatet.
Neste skritt ville være
cosinus-avstand, og for hvert skritt oppover i kompleksitet, desto mer treffsikre er de gjerne disse algoritmene. Cosinus-avstand regnes ut slik
Cosinus-avstand er også mye brukt innen programmering, og er ting man burde kunne, og det er mye enklere å skrive en slik funksjon enn formelen ovenfor skulle tilsi.
Enda et skritt opp ville være noe slikt som
Jaccard, men det er nok ikke så mye brukt, og enda litt bedre er
K-means, en algoritme som også er veldig mye brukt i programmering til sammenligninger, men mest til det som kalles "clustering", for eksempel til å sammenligne ting som titler i artikler og slikt.
Grunnen til at jeg vet en del om dette, er nettopp fordi jeg en gang laget en nyhetsaggregator, altså en dings som henter nyheter fra de største nyhetsnettsidene, og da vil man gjerne samle artikler om samme emne.
Det høres jo veldig enkelt ut i prinsippet, dersom to artikler er om samme sak, så setter vi de i samme bås.
Men, det tok flere uker å lære alle disse algoritmene, og så skrive en egen versjon av K-means som lagrer og vekter ord osv.
Som et raskt eksempel, så er det er ikke sikkert at VG og Dagbladet benytter samme tittel på to artikler om samme emne, en nettavis skriver kanskje
"Erna på tokt med forsvaret", mens den andre skriver
"Forvaret hadde med Erna på tokt".
Artiklene er helt klart om det samme emnet, men dersom man sammenligner tegn for tegn fra start til slutt, så blir det "epic fail", de er ikke like i det hele tatt, og alle algoritmene som sammenligner tegn vil stort sett feile på den slags sammenligninger.
Der kommer ting som K-means inn, og sammen med en vektet liste med ord så kan man regne ut at ordene
"erna", "tokt" og
"forsvaret" ikke brukes så ofte, det vil si, alle ord gies en poengsum, og så ser man også på tidsperspektivet i tillegg og kan se at artiklene er publisert samme dag, innen et vist angitt tidsrom, og derfor omhandler begge artiklene sannsynligvis den samme nyhetssaken og kan samles.
Så lærte vi noe i dag også!
Til ditt bruk vil det vel holde å gjøre om begge til samme case, altså kjøre en toLowerCase/str_to_lower funksjon på begge to dersom det skal være case-insensitive, og så kjøre en Levenshtein sammenligning for å se hvilke av alternativene som er best match til det som ble skrevet inn osv. og derfor la jeg ved både en javascript versjon og lenke til PHP sin innebygde, ettersom det er en av de du sannsynligvis ender opp med.

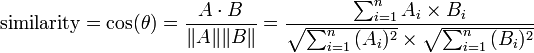
")